ўвядзенне
У гэтым раздзеле:
- агляд;
- спрашчэнне, выключэнне супярэчнасцяў і лішніх злучэнняў;
- прагляд дрэва лагічных аперацый;
У дадзенай нататцы разглядаюцца некаторыя механізмы працы аптымізатар. Яна будзе цікавая тым, хто хоча больш даведацца аб працэсе пераўтварэння запыту ў план запыту, які і будзе перададзены серверу на выкананне.
Многія сродкі, якія выкарыстоўваюцца ў нататцы - недокументированны, па гэтым, ні ў якім разе не рэкамендуецца ўжываць іх на «баявых» серверах. Таксама, калі вы хочаце выконваць прыведзеныя ў нататцы запыты, то рэкамендуецца версія сервера для эксперыментаў «Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600», інакш вынік можа адрознівацца.
Такім чынам, непасрэдна да справы.
Працэс аптымізацыі складаецца з наступных крокаў.
1. Parsing
2. Binding
3. Optimization
3.1 Simplification
3.2 Trivial Plan Optimization
3.3 Full Optimization
3.3.1 Search 0
3.3.2 Search 1
3.3.3 Search 2
4. Execution
Parsing - на дадзеным этапе вырабляецца разбор тэксту запыту, праверка сінтаксісу і пабудова дрэва лагічных аператараў. На выхадзе з дадзенага этапу аптымізатар атрымлівае parsed tree.
Binding - на этапе звязвання, вырабляецца дазвол імёнаў, праверка на існаванне табліц, калонак і іншых аб'ектаў і супастаўленне кожнага аб'екта дрэва з рэальным аб'ектам сістэмнага каталога.
Optimization: Simplification - этап спрашчэння дрэва. Ён уключае ў сябе наступныя функцыі:
- разгортванне подзапросов ў злучэнні (тых, што магчыма);
- выдаленне залішніх злучэнняў;
- фільтры з where «прапіхваў» ўніз па дрэве, каб забяспечыць ранняе фільтраванне;
- выяўляюцца і выключаюцца супярэчнасці.
На выхадзе з гэтай стадыі атрымліваецца спрошчанае дрэва лагічных аператараў.
Optimization: Trivial Plan Optimization - пошук трывіяльнага плана. Калі запыт можа быць вырашана адзіным або відавочна адзіна лепшым спосабам, то значыць, запыт задавальняе ўмове трывіяльнага плана. На дадзеным этапе не выкарыстоўваюцца рашэння на аснове статыстык, кошту і г.д. Выкарыстоўваецца толькі інфармацыя пра схему БД (хоць гэта не зусім так і мы паглядзі на гэта пазней). На кожным этапе, пачынаючы з гэтага, аптымізацыя можа быць завершана, калі знойдзены дастаткова добры план, які задавальняе унутраным парога аптымізатар.
Optimization: Full Optimization: Search 0 - гэтую стадыю таксама называюць transaction processing - яна перасьледуе такую ж мэта, як і пошук трывіяльнага плана, знайсці добры план за мінімальны час. На гэтым этапе, аптымізатар, на аснове эўрыстыкі, генеруе пачатковыя наборы магчымых варыянтаў злучэння, пачынаючы з злучэння найбольш дробных (ці добра адфільтраваць на ранняй стадыі) табліц. Гэты парадак, як правіла, адзіны, які выкарыстоўваецца на дадзеным этапе. Калі пасля гэтай стадыі дастаткова добры план не знойдзены, то кіраванне пераходзіць да наступнай стадыі. Дадзеная стадыя можа быць прапушчана, і аптымізатар адразу можа перайсці да стадыі 1, калі запыт не задавальняе вызначаным умовам.
Optimization: Full Optimization: Search 1 - гэтая стадыя гэтак жа вядомая як Quick Plan. На дадзеным этапе выкарыстоўваюцца дадатковыя правілы пераўтварэння і некаторыя магчымыя перастаноўкі варыянтаў злучэння. Калі пасля генерацыі плана на гэтай стадыі, план ўсё яшчэ не дастаткова добры, то дадзеная стадыя паўтараецца з мэтай пошуку паралельнага плана. Пасля чаго два пляны параўноўваюцца, і для ацэнкі выбіраецца лепшы з іх. Калі гэты лепшы план ўсё яшчэ не праходзіць ўнутраныя парогі аптымізатар, то кіраванне пераходзіць да наступнай стадыі.
Optimization: Full Optimization: Search 2 - гэтая стадыя вядомая як Full. Самая апошняя стадыя, а значыць, на ёй, план павінен быць атрыманы ў любым выпадку, нават калі ён здаецца аптымізатар ўсё яшчэ недастаткова добрым. Гэтая стадыя выкарыстоўваецца для складаных і вельмі складаных запытаў.
Створым на тэставым серверы, тэставую БД і табліцы (тут і далей я не буду казаць схему, маючы на ўвазе, што ўсе аб'екты знаходзяцца ў схеме dbo).
create database opt; go use opt; go create table t1 (a int primary key, b int not null, c int check (c between 1 and 50)); create table t2 (b int primary key, c int, d char (10)); create table t3 (c int primary key); go insert into t1 (a, b, c) select number, number% 100 + 1, number% 50 + 1 from master..spt_values where type = 'p' and number between 1 and 1000; insert into t2 (b, c) select number, number% 100 + 1 from master..spt_values where type = 'p' and number between 1 and 1000; insert into t3 (c) select number from master..spt_values where type = 'p' and number between 1 and 1000; go alter table t1 add constraint fk_t2_b foreign key (b) references t2 (b);
Цяпер, давайце разгледзім кожную стадыю Optimization больш падрабязна. Па меры таго, як мы будзем пазнаваць новыя сродкі даследаванні, мы будзем вяртацца да запытаў папярэдняй стадыі для пацверджання высноў.
Такім чынам, прыступім!
Optimization: Simplification
Паглядзім на гэтую фазу больш дэталёва. Ўключым опцыю Include Actual Plan і выканаем наступны запыт:
select t1.b, t1.c from t1 join t2 on t1.b = t2.b outer apply (select c from t3 where c = 1) t3 where t1.a = 200 and t1.c between 1 and 50 option (recompile )
Што мы можам чакаць у плане, калі разважаць лагічна. Па-першае, злучэнне табліц t1 і t2, па ўмове роўнасці слупкоў t1.b = t2.b, па-другое, для атрыманага выніку выкананне подзапросов з outer apply для кожнага радка, пасля чаго фільтрацыю па прэдыкаты t1.a = 200 і t1 .c between 1 and 50.
Але замест гэтага мы бачым:

Г.зн. аптымізатар звёў усе да простага пошуку па кластарнай індэксе адной табліцы. Давайце разбярэмся, чым ён кіраваўся, калі гэта рабіў.
Пачнем з злучэння табліцы t2. Калі мы паглядзім на запыт, то нідзе не ўбачым, каб у выніках патрабавалася хоць адна калонка з t2. Але гіпатэтычна табліца t2 ўсё яшчэ можа ўплываць на вынік запыту, напрыклад, паменшыўшы або павялічыўшы лік радкоў, за кошт ўмовы злучэння. Аднак, узгадаем, як мы вызначылі табліцу t1, слупок b там вызначаны як b int not null, г.зн. ў ім абавязкова павінна ўтрымлівацца нейкае значэнне, а, такім чынам, пры злучэнні па ім, выніковае лік радкоў не можа зменшыцца (калі няма дадатковых фільтраў у where, вядома, але ў нас іх няма). Але можа быць яно можа павялічыцца? Але ўспомнім, што слупок t2.b вызначаны як primary key, які змяшчае толькі унікальныя значэння. Гэтак жа ўспомнім, што за кошт абмежавання знешняга ключа fk_t2_b, у табліцы t1 ў Стоўбцах b не могуць з'яўляцца ніякія іншыя значэнні, акрамя як з табліцы t2. Што мы атрымліваем у выніку, у выніковым запыце слупкоў з t2 няма, ва ўмове злучэння табліца t2 ні на што не ўплывае, бо не можа ні дадаць, ні выдаліць радкоў, а значыць, можна яе выключыць!
Зараз разбяромся з apply. Бо мы выкарыстоўваем outer apply, а не cross apply, то колькасць радкоў не можа зменшыцца, нават калі подзапросов select c from t3 where c = 1 ня знойдзе ні аднаго радка для ўмовы c = 1. Ці могуць радкі быць дададзеныя, калі подзапросов верне больш аднаго значэння? Няма, бо у нас ўмова строгага роўнасці, а па полі t3.c у нас ёсць першасны ключ, а значыць, будзе абраная максімум адзін радок. Такім чынам, мы атрымліваем пахаджу сітуацыю, спасылак на калонкі табліцы t3 ў выніковым выразе select няма, аперацыя apply не ўплывае на колькасць радкоў у выніковым наборы, а значыць можна яе выключыць зусім!
Зараз пераходзім да секцыі where. Паглядзім на прэдыкатаў t1.c between 1 and 50. Чаму мы не бачым гэтага параўнання ў плане? Справа ў тым, што калі ўспомніць, то мы пры вызначэнні табліцы t1 задалі абмежаванне c int check (c between 1 and 50), зыходзячы з яго, у гэтым слупку наогул не могуць утрымлівацца іншыя значэнні, так навошта ж яшчэ раз гэта правяраць? Па гэтым, гэта ўмова выключаецца з плана. Больш за тое, калі вы зменіце ў запыце ўмова, напрыклад, на t1.c between 100 and 150, то ў вас план прыме і зусім такі выгляд:

Г.зн. доступ да табліцах не будзе ажыццяўляцца увогуле, бо загадзя няма значэнняў, якія б задавальнялі такому умове. Пры гэтым, зразумела, усе абмежаванні павінны быць «даверанымі», пра гэта я пісаў тут.
Пяройдзем да наступнага умове, t1.a = 200, чаму мы не бачым аператар Filter? Тут, справа ў тым, што аптымізатар як бы «прапіхваў» гэты прэдыкатаў, на больш раннюю стадыю (да выканання злучэння), на стадыю выбару радкоў з табліцы t1. Сапраўды, навошта злучаць ўсе радкі, а затым фільтраваць, калі можна адразу абраць для злучэння толькі патрэбныя, пры дапамозе азначніка. Гэты прыём вядомы як predicate pushdown.
Што ў выніку. У выніку застаецца адзіная аперацыя, выканаць пошук патрэбных дадзеных у кластарных індэксе, прычым, гэта адзіная самая лепшая стратэгія якая ўжываецца ў дадзеным выпадку, а значыць, план задавальняе умовам trivial plan, і аптымізацыя на гэтым сканчаецца.

Да этапу пошук трывіяльнага плана мы вернемся крыху пазней, а пакуль зірнем на іншы запыт.
select t1.b, t1.c, d = (select min (c) from t3 where t1.c = t3.c) from t1 option (recompile)
Што б мы маглі чакаць у гэтым выпадку? У гэтым выпадку можна было б чакаць прагляд табліцы t1, пасля чаго, для кожнай знойдзенай радкі выкананне подзапросов да табліцы t3 з агрэгацыяй. Што мы бачым у выніку:
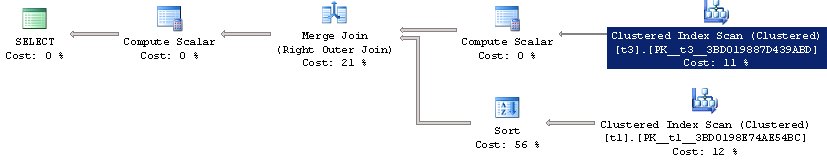

У выніку, мы бачым, што было выканана сканаванне ўсёй табліцы t3, прычым зьвярніце ўвагу, зроблена гэта ўсяго 1 раз. Пасля чаго вынікі для абодвух табліц былі аб'яднаны. Г.зн. аптымізатар зразумеў, што не трэба выконваць адно і тое ж 1000 разоў, можна загадзя вылічыць вынік і злучыць з табліцай t1, г.зн. ён «раскрыў» наш подзапросов (unnest sub query).
Цяпер, дадамо ўсяго адно слова, якое не зменіць вынік і логіку, і зноў зірнем на план
select t1.b, t1.c, d = (select top (1) min (c) from t3 where t1.c = t3.c) from t1 option (recompile)

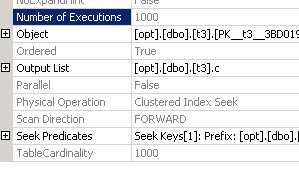
Тут мы бачым, што план кардынальным чынам памяняўся. Цяпер, сапраўды выконваецца прагляд табліцы t3 і для кожнай атрыманай радкі (у дадзеным выпадку ў нас 1000 радкоў) выконваецца пошук па індэксе ў табліцы t3, пасля чаго агрэгавання і выбар аднаго радка. Усё гэта адбываецца 1000 разоў. Г.зн. запыт, ня быў разгорнуты, а застаўся подзапросов. Чаму так?
Справа ў тым, што аптымізатар не схільны выконваць аперацыю unnest для подзапросов з top. Аб гэтай асаблівасці ведаюць і выкарыстоўваюць яе пры напісанні t-sql кода, пра гэта выкарыстанні таксама ведаюць і распрацоўшчыкі сіквел сервера, па гэтым, пакуль не спяшаюцца яе мяняць, але ў будучых версіях ад такіх зменаў ніхто не застрахаваны.
Напрыканцы, маленькая рэмарка па прадукцыйнасці. Я думаю, вы ўжо здагадаліся, але ўсё ж, прывяду колькасць чытанняў і параўнальную кошт планаў для абодвух запытаў.
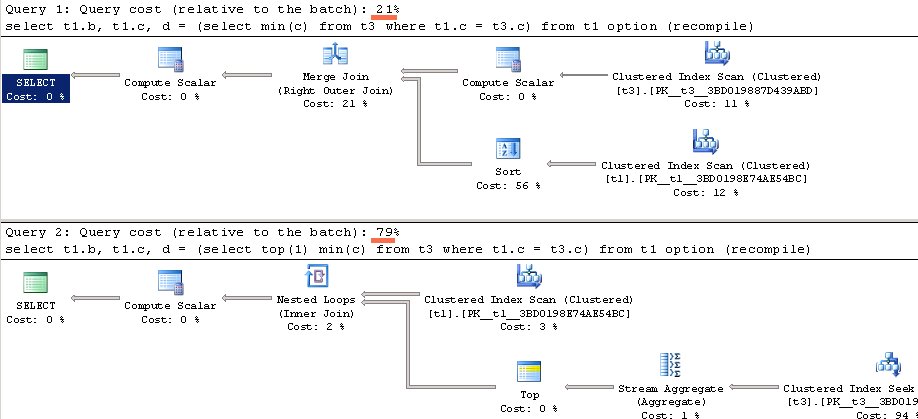
І колькасць чытанняў адпаведна
(1000 row (s) affected) Table 't1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 't3'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row (s) affected) (1000 row (s) affected ) Table 't3'. Scan count 0, logical reads 2000, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 't1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row (s) affected)
Такім чынам, мы паглядзелі на некаторыя этапы фазы спрашчэння. Ок, тэорыя нібыта выглядае пераканаўча і пацвярджаецца практычна. Але ці можна даведацца, ці сапраўды ўсё так адбываецца ці не?
Ды і больш за тое, пабачыць на свае вочы. У гэтым нам дапамогуць недакументаваныя сцягі трасіроўкі. Адзін з іх, шырока вядомы 3604, ён перанакіроўвае выснову некаторых карысных каманд з лога на кансоль. Іншы, меней вядомы, 8606 ён пакажа нам, як пераўтворыцца дрэва лагічных аператараў.
Вернемся да першага запыце і выканаем яго з гэтымі сцягамі.
select t1.b, t1.c from t1 join t2 on t1.b = t2.b outer apply (select c from t3 where c = 1) t3 where t1.a = 200 and t1.c between 1 and 50 option (recompile , querytraceon 3604, querytraceon 8606)
Далей пераключымся на ўкладку Messages і мы ўбачым вельмі цікавую карціну. Для выгоды я разбіў выснову службовай інфармацыі на тры карцінкі з тлумачэннямі, а пэўную частку апусьціў.
Такім чынам, вось што мы ўбачым:

Наступная фаза, спрошчанае дрэва:

На гэтым этапе мы бачым, што быў цалкам выключаны аператар apply і зварот да табліцы t3, а так жа прэдыкатаў t1.c between 1 and 50. Але з'явіўся новы лагічна аператар, які правярае, што значэння ў калонцы c не роўныя null. Чаму? Таму, што мы вызначылі для калонкі дыяпазон ад 1 да 50, але сама калонка ў нас nullable, і такім чынам, хоць і не мае сэнсу правяраць дыяпазон, бо ён забяспечваецца абмежаваннем check (c between 1 and 50), але гэты прэдыкатаў ўсё яшчэ можа паўплываць на выніковы набор выключыўшы радкі са значэннем null ў калонцы c. Калі б мы спачатку вызначылі б c як not null - гэта галінка б таксама знікла цалкам. Вы можаце гэта самі праверыць, перавызначыць гэтую калонку як not null.
На гэтым этапе па-ранейшаму засталося «лішняе» злучэнне з табліцай t2.
Пераходзім да наступнага этапу Join-Collapse, выключэнню лішніх злучэнняў.

На гэтым этапе мы пазбавіліся і ад табліцы t2. Цяпер, усё што ў нас засталося ў дрэве лагічных аператараў, гэта атрыманне дадзеных з табліцы t1, параўнанне з канстантнасцю 200 і праверка калонкі c на not null.
На гэтым, у нашым прыкладзе, этап спрашчэння завяршаецца.
Ок, мы многае ўбачылі, але пытанні яшчэ засталіся, першае - як менавіта аптымізатар «здагадаўся» ўжыць усе гэтыя пераўтварэнні, і другое - усё-такі, execution engine аперыруе не лагічным дрэвам, а значыць, гэта не канчатковы этап і далей таксама што- то адбываецца, дзе, калі і як адбываецца пераўтварэнне лагічнага дрэва ў фізічныя аператары. Адказы на гэтыя пытанні, я паспрабую даць у наступных раздзелах прысвечаных далейшай аптымізацыі.
1. Ці могуць радкі быць дададзеныя, калі подзапросов верне больш аднаго значэння?
50. Чаму мы не бачым гэтага параўнання ў плане?
1.a = 200, чаму мы не бачым аператар Filter?
Чаму так?
Але ці можна даведацца, ці сапраўды ўсё так адбываецца ці не?
Чаму?



