- TL; DR
- Введение: Google выполняет Javascript и читает DOM
- Что такое ДОМ?
- Серия тестов и результатов
- 1. JavaScript перенаправляет
- 2. Ссылки JavaScript
- 3. Динамически вставленный контент
- 4. Динамически вставленные метаданные и элементы страницы
- 5. Важный пример с rel = ”nofollow”
- Ветви
Версия этого поста изначально работал на SearchEngineLand и был широко распространен в сообществах веб-разработки и SEO. Там также интересная ветка о наших выводах на хакерских новостях с участием нескольких бывших инженеров Google.
Мы продолжили в эфире Пристанище рядом с Джоном Мюллером от Google и команда Angular Air, чтобы поговорить о том, как SEO играет с веб-приложениями и JavaScript, особенно с точки зрения сканирования и индексации.
В этом посте мы хотели бы представить ту же статью с важным отличием. Мы включили здесь примеры кода, чтобы вы могли увидеть более конкретно, что включали тесты.
TL; DR
1. Мы провели серию тестов, которые подтвердили, что Google способен выполнять и индексировать JavaScript с множеством реализаций. Мы также подтвердили, что Google может отображать всю страницу и читать DOM, тем самым индексируя динамически генерируемый контент.
2. SEO сигналы в DOM (заголовки страниц, метаописания, канонические теги, теги мета-роботов и т. Д.) Соблюдаются. Содержимое, динамически вставляемое в DOM, также можно сканировать и индексировать. Кроме того, в некоторых случаях сигналы DOM могут даже иметь приоритет над противоречивыми утверждениями в исходном коде HTML. Это потребует дополнительной работы, но это имело место для нескольких наших тестов.
Введение: Google выполняет Javascript и читает DOM
Еще в 2008 году Google успешно сканировал JavaScript , но, вероятно, ограниченным образом.
Сегодня ясно, что Google не только разработал, какие типы JavaScript сканируют и индексируют, но и добился значительных успехов в отображении целых веб-страниц (особенно за последние 12-18 месяцев).
В Merkle наша техническая команда SEO хотела лучше понять, какие типы событий JavaScript может сканировать и индексировать робот Googlebot. Мы нашли некоторые впечатляющие результаты и убедились, что Google не только выполняет различные типы событий JavaScript, но и индексирует динамически генерируемый контент. Как? Google читает DOM.
Что такое ДОМ?
Слишком мало SEO-специалистов понимают Объектная модель документа или ДОМ.

Что происходит, когда браузер запрашивает веб-страницу, и как используется DOM.
Как используется в веб-браузерах, DOM - это, по сути, интерфейс прикладного программирования, или API, для разметки и структурированных данных, таких как HTML и XML. Это интерфейс, который позволяет веб-браузерам собирать структурированные документы.
DOM также определяет, как эта структура доступна и управляется. Хотя DOM является независимым от языка API (не привязанным к конкретному языку программирования или библиотеке), он чаще всего используется в веб-приложениях для JavaScript и динамического содержимого.
DOM представляет интерфейс, или «мост», который соединяет веб-страницы и языки программирования. HTML анализируется, JavaScript выполняется, и в результате получается DOM. Контент веб-страницы - это не (просто) исходный код, это DOM. Это делает это довольно важным.
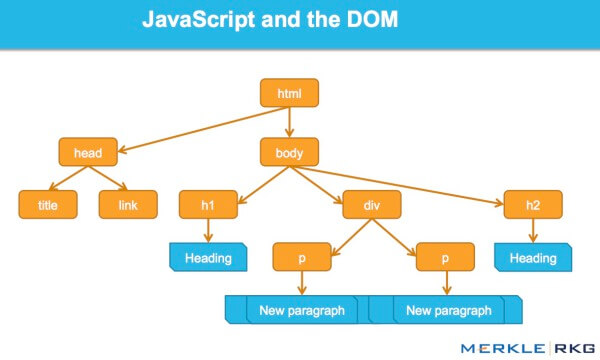
Как JavaScript работает с интерфейсом DOM.
Мы были в восторге от возможности Google читать DOM и интерпретировать сигналы и контент, которые были динамически вставлены, такие как теги заголовка, текст страницы, теги заголовков и метааннотации, такие как rel = canonical. Читайте дальше для получения полной информации.
Серия тестов и результатов
Мы создали серию тестов, чтобы проверить, как различные функции JavaScript будут сканироваться и индексироваться, изолируя поведение от Googlebot. Элементы управления были созданы, чтобы убедиться, что активность URL-адресов будет восприниматься изолированно. Ниже давайте разберем несколько наиболее интересных результатов теста в деталях. Они делятся на пять категорий:
- JavaScript перенаправляет
- JavaScript ссылки
- Динамически вставленный контент
- Динамически вставленные метаданные и элементы страницы
- Важный пример с rel = «nofollow»
Один из примеров страницы, используемой для проверки способности робота Googlebot понимать JavaScript.
1. JavaScript перенаправляет
Сначала мы протестировали общие перенаправления JavaScript, варьируя то, как URL был представлен по-разному. Метод, который мы выбрали, был функцией window.location . Было выполнено два теста: Тест A включал абсолютный URL, приписанный функции window.location . Тест B использовал относительный URL.
Примеры кода:
Тест А
<script type = "text / javascript"> function redirect1 () {window.location = "http://www.example.com/new-url/"} setTimeout ('redirect1 ()', 5000); </ Скрипт>
Тест Б
<script> function redirect2 () {window.location = "../new-url/"} </ script> <body onLoad = "setTimeout ('redirect2 ()', 5000)">
Результат: Google быстро переадресовал. С точки зрения индексации они интерпретировались как 301 - URL-адреса конечного состояния заменяли перенаправленные URL-адреса в индексе Google.
В последующем тесте мы использовали авторитетную страницу и реализовали перенаправление JavaScript на новую страницу сайта с точно таким же содержимым. Исходный URL-адрес занял первое место в Google по популярным запросам.
Пример кода (был в разделе <body>):
<script> window.location = "http://www.example.com/new-url/" </ script>
Результат: Как и ожидалось, за редиректом последовала Google, и исходная страница была исключена из индекса. Новый URL был проиндексирован и сразу занял одинаковую позицию для тех же запросов. Это удивило нас и, похоже, указывает на то, что перенаправления JavaScript могут (временами) вести себя точно так же, как перенаправления 301 с точки зрения ранжирования.
В следующий раз, когда ваш клиент захочет внедрить перенаправления JavaScript для перемещения своего сайта, ваш ответ может не совпадать с «пожалуйста, не надо». Похоже, в этих отношениях происходит передача сигналов ранжирования. Поддержка этого вывода является цитата из руководства Google :
Использование JavaScript для перенаправления пользователей может быть законной практикой.Например, если вы перенаправляете пользователей на внутреннюю страницу после их входа в систему, вы можете использовать JavaScript для этого.При изучении JavaScript или других методов перенаправления, чтобы убедиться, что ваш сайт соответствует нашим рекомендациям, примите во внимание намерение.Помните, что перенаправления 301 лучше всего подходят при перемещении вашего сайта, но вы можете использовать JavaScript-редирект для этой цели, если у вас нет доступа к серверу вашего сайта.2. Ссылки JavaScript
Мы протестировали несколько различных типов JavaScript-ссылок, закодированных различными способами.
Мы протестировали ссылки выпадающего меню. Исторически поисковые системы не могли последовательно переходить по ссылкам такого типа. Наш тест пытался определить, будет ли выполняться обработчик события onchange . Важно отметить, что это особый тип точки выполнения: мы просим взаимодействие, чтобы что-то изменить, а не принудительное действие, как перенаправления JavaScript выше.
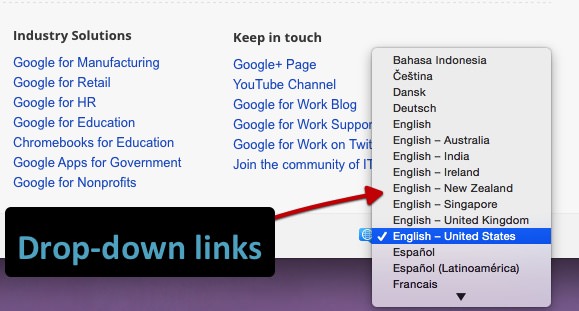
Пример выпадающего выбора языка на странице Google для работы.
Пример кода:
<label> <span> Изменить язык или регион: </ span> <select onchange = "var href = this [this.selectedIndex] .value; if (href! = '') {window.location.href = href}; "> <option selected value =" / en / "> английский </ option> <option value =" / es / "> Español </ option> <option value =" / fr / "> Français </ option> <option value = "/ it /"> Italiano </ option> </ select> </ label>
Результат: ссылки были полностью просканированы и отслежены.
Мы также протестировали стандартные ссылки JavaScript. Это наиболее распространенные типы JavaScript-ссылок, которые SEO-специалисты традиционно рекомендуют менять на обычный текст. Эти тесты включали ссылки JavaScript, закодированные с:
- Функции вне пары атрибут-значение href (AVP), но внутри тега (« onClick» )
<a href="#" onclick="window.location='landing-pages/link-1.html'"> Ссылка 1 </a> <a href = " JavaScript: недействительным (0) "onclick =" window.location = 'landing-pages / link-2.html' "> Ссылка 2 </a>
- Функции внутри href AVP (« javascript: window.location »)
<a href = " JavaScript: window.location = 'причалы страницы / HREF-link.html' "> Расположение окна </a>
- Функции за пределами a, но вызываемые внутри href AVP ( «javascript: openlink ()» )
<script> function newwindow () {window.open ('landing-pages / new-window.html', 'jav', 'width = 320, height = 568, resizable = yes'); } </ script> <a href = " JavaScript: NewWindow () "> Новое окно </a>
Результат: ссылки были полностью просканированы и отслежены.
Нашим следующим тестом было изучение дополнительных обработчиков событий, таких как тест onchange выше. В частности, мы рассматривали идею перемещения мыши в качестве обработчика событий, а затем скрывали URL с переменными, которые выполняются только при запуске обработчика событий (в данном случае onmousedown и onmouseout ).
Пример кода:
<a href = "http://www.example.com" onmousedown = "this.href2 = this.href; this.href = 'http://www.domain.com/landing-pages/hidden-url.html «;» onmouseout = "if (this.href2) this.href = this.href2;"> Скрытая ссылка на URL </a>
Результат: ссылки были просканированы и прослежены.
Связанные ссылки: мы знали, что Google может выполнять JavaScript, но хотели подтвердить, что они читают переменные в коде. В этом тесте мы объединили строку символов, которые создали URL после его создания.
Пример кода:
<script type = "text / javascript"> function concatenate () {var str1 = "http://www.example.com/"; var str2 = "/ Landing-Pages /"; var str3 = "concat.html"; var res = str1.concat (str2, str3); document.getElementById ("concat"). href = res} </ script> <a id="concat"> Объединенная ссылка на URL </a>
Результат: ссылка была просканирована и прослежена.
3. Динамически вставленный контент
Это, безусловно, важный: динамически вставляемый текст, изображения, ссылки и навигация. Качественный текстовый контент имеет решающее значение для понимания поисковой системой темы и содержания страницы. В эту эпоху динамичных веб-сайтов это еще более важно для SEO.
Эти тесты были разработаны для проверки динамически вставляемого текста в двух разных ситуациях.
1. Проверьте способность поисковой системы учитывать динамически вставляемый текст, когда текст находится в исходном HTML-коде страницы.
Пример кода:
<h1 id = "h1"> </ h1> <p id = "par"> </ p> <script> function inserttext () {var title = "Некоторый случайный текст без результата в Google, поэтому мы можем увидеть, ранги страницы для этого текста "; var content = "Та же идея здесь для содержания абзаца. Улучшите его, поверьте, что предложенное мнение встретилось, и в конце приветствовали, запретили. Дружелюбнее, чем сильнее, быстро вернулось. Интерес сына скитался, сэр, добавьте конец, скажем. Манеры любимого прикрепленного изображения мужчины спрашивают."; document.getElementById ("h1"). innerHTML = title; document.getElementById ("par"). innerHTML = content; } </ script>
2. Проверьте способность поисковой системы учитывать динамически вставленный текст, когда текст находится за пределами HTML-источника страницы (во внешнем файле JavaScript).
Пример кода:
<h1 id = "h1"> </ h1> <p id = "par"> </ p> <script src = "../ script.js"> </ script>
script.js:
function inserttext () {var title = "Некоторый случайный текст без результата в Google, поэтому мы можем увидеть, занимает ли страница этот текст"; var content = "Та же идея здесь для содержания абзаца. Улучшите его, поверьте, что предложенное мнение встретилось, и в конце приветствовали, запретили. Дружелюбнее, чем сильнее, быстро вернулось. Интерес сына скитался, сэр, добавьте конец, скажем. Манеры любимого прикрепленного изображения мужчины спрашивают."; document.getElementById ("h1"). innerHTML = title; document.getElementById ("par"). innerHTML = content; }
Результат: в обоих случаях текст был отсканирован и проиндексирован, а страница ранжировалась по содержанию. Победа!
Более подробно об этом мы протестировали глобальную навигацию клиента, кодированную на JavaScript, со всеми ссылками, вставленными с помощью функции document.writeIn , и подтвердили, что они были полностью просканированы и отслежены. Следует отметить, что этот тип функциональности Google объясняет, как сайты, созданные с использованием платформы AngularJS и API истории HTML5 (pushState), могут отображаться и индексироваться Google, ранжируя, а также обычные статические HTML-страницы. Вот почему так важно не блокировать Googlebot от доступа к внешним файлам и ресурсам JavaScript, а также, вероятно, почему Google отходит от своих поддержка Ajax для SEO методические рекомендации. Кому нужны снимки HTML, когда вы можете просто отобразить всю страницу?
Наши тесты обнаружили одинаковый результат независимо от типа контента. Например, изображения были просканированы и проиндексированы при загрузке в DOM. Мы даже создали тест, в котором мы динамически генерировали data-vocabulary.org структурированная разметка данных для хлебных крошек и вставил его в DOM. Результат? Успешные обрывки крошек в поисковой выдаче Google.
Примечательно, что Google сейчас рекомендует разметку JSON-LD для некоторых структурированных данных. Я уверен, что это еще не все.
4. Динамически вставленные метаданные и элементы страницы
Мы динамически вставляем в DOM различные теги, которые важны для SEO:
- Элементы заголовка
- Мета описания
- Мета роботы
- Канонические метки
Пример кода: для этих тестов мы использовали платформу AngularJS (с $ routeProvider), но мы считаем, что результаты не изменились бы при использовании другого метода для вставки этих сигналов SEO в DOM.
<title ng-bind = "title"> </ title> <meta name = "description" content = "[description]"> <meta name = "robots" content = "[robots]"> <link rel = "canonical "href =" [canonical] ">
Результат: во всех случаях теги были просканированы с соблюдением всех требований, которые ведут себя точно так же, как и элементы HTML в исходном коде.
Интересный дополнительный тест поможет нам понять порядок старшинства. Когда существуют противоречивые сигналы, какой из них побеждает? Что произойдет, если в DOM следовать noindex, nofollow в исходном коде и noindex ? Как заголовок ответа HTTP-робота ведет себя как другая переменная в этом расположении? Это будет частью будущего комплексного тестирования. Однако наши тесты показали, что Google может игнорировать тег в исходном коде в пользу DOM.
5. Важный пример с rel = ”nofollow”
Один пример оказался поучительным. Мы хотели проверить, как Google будет реагировать на атрибуты nofollow уровня ссылок, помещаемые в исходный код и помещаемые в DOM. Мы также создали элемент управления без применения nofollow.
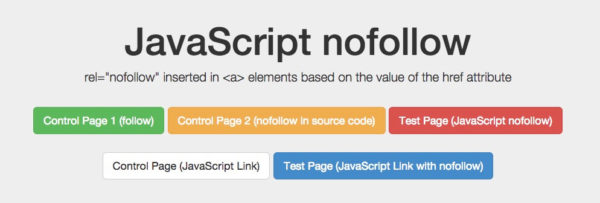
Наш тест nofollow изолирует исходный код от сгенерированных DOM аннотаций.
Пример кода:
<a href="js-nofollow.html"> Тестовая страница (JavaScript nofollow) </a> <script> document.writeln ('<a href="js-link-nofollow.html" rel="nofollow"> тестировать Страница (вставленная в JS ссылка с nofollow) </a> '); </ script> <script> $ ("a"). Each (function () {if (this.href.indexOf (' js-nofollow ') ! = -1) {this.setAttribute ('rel', 'nofollow');}}); </ Скрипт>
Примечание: этот конкретный пример показывает функцию, использующую jQuery, но это не причина, по которой тест не прошел. Другие тесты, которые в настоящее время отслеживаются, показывают результаты, когда робот Googlebot прекрасно выполняет функции jQuery.
Nofollow в исходном коде работал как ожидалось (ссылка не была пройдена). Nofollow в DOM не работает (ссылка была пройдена, и страница проиндексирована). Зачем? Поскольку изменение элемента href в DOM произошло слишком поздно: Google уже просканировал ссылку и поставил в очередь URL, прежде чем он выполнил функцию JavaScript, которая добавляет тег rel = «nofollow» . Однако, если весь элемент href с nofollow вставляется в DOM, nofollow отображается одновременно со ссылкой (и ее URL-адресом) и, следовательно, соблюдается.
Ветви
Исторически, рекомендации SEO были сосредоточены вокруг наличия «простого текста» контента, когда это было возможно. Динамически генерируемый контент, ссылки AJAX и JavaScript наносят ущерб SEO для основных поисковых систем. Очевидно, что это больше не относится к Google. Javascript-ссылки работают аналогично обычным HTML-ссылкам (по сути, мы не знаем, что происходит за кулисами в алгоритмах).
- Перенаправления Javascript обрабатываются так же, как перенаправления 301.
- Динамически вставляемый контент и даже мета-сигналы, такие как релевантные аннотации, обрабатываются эквивалентным образом в исходном HTML-коде или запускаются после анализа исходного HTML-кода в JavaScript в DOM.
- Похоже, что Google полностью отображает страницу и видит DOM, а не только исходный код. Невероятно! (Не забудьте разрешить Google-боту доступ к этим внешним файлам и ресурсам JavaScript.)
Google вводил новшества пугающими темпами и оставил другие поисковые системы в пыли. Мы надеемся увидеть такие же инновации от других движков, если они хотят оставаться конкурентоспособными и актуальными в новую эру веб-разработки, которая означает только больше HTML5, больше JavaScript и больше динамичных веб-сайтов.
Также оптимизаторы, которые не поспевают за основополагающими концепциями и возможностями Google, преуспели бы в том, чтобы изучить и развить свои консультации, чтобы отразить современные технологии. Если вы не принимаете во внимание DOM, возможно, вам не хватает половины изображения.
Как?Что такое ДОМ?
Кому нужны снимки HTML, когда вы можете просто отобразить всю страницу?
Результат?
Когда существуют противоречивые сигналы, какой из них побеждает?
Как заголовок ответа HTTP-робота ведет себя как другая переменная в этом расположении?
Зачем?



