- Обзор и индексирование с первого взгляда Возьмите под контроль процесс сканирования и индексации...
- Как работает индексирование?
- Как взять под контроль сканирование и индексирование
- Файл Robots.txt
- Полезный чит для просмотра и индексации
- Канонические URL
- Атрибут Hreflang
- Пейджинг: rel = «prev» и rel = «next»
- Rel = «альтернативный» мобильный атрибут
- Полезный чит для просмотра и индексации
- Просматривайте сайт как поисковик: ставьте себя в свои шкуры
- Другие ситуации, когда удобно использовать Load as Google
- Наиболее часто задаваемые вопросы о сканировании и индексации
- 2. Могу ли я замедлить работу роботов при просмотре моего сайта?
- 3. Как я могу запретить роботам просматривать сайт или сайт?
- 4. Что означает индексация сайта?
- 5. Индексируется ли мой сайт поисковым системам?
- 6. Как часто Google индексирует мой сайт?
- 7. Сколько времени Google тратит на индексацию новых сайтов?
- 8. Как я могу запретить поисковым системам индексировать сайт или сайт?
Обзор и индексирование с первого взгляда
Возьмите под контроль процесс сканирования и индексации своего сайта, сообщив поисковым системам, каковы ваши предпочтения.
Это поможет им понять, на каких частях вашего сайта они должны сосредоточиться, и, наоборот, игнорировать. Есть много методов для этого, так когда вы используете какой метод?
В этой статье мы обсудим какие методы использовать и оценим все за и против.
Поисковые системы просматривают миллиарды страниц каждый день. Но они гораздо менее проиндексированы, и еще меньше будет появляться в результатах поиска. И вы хотите, чтобы ваш сайт был среди них. Итак, как взять под контроль весь этот процесс и улучшить свою позицию?
Чтобы ответить на этот вопрос, сначала нужно посмотреть, как работает процесс сканирования и индексации . Затем вместе мы рассмотрим доступные методы, которые вы можете использовать для управления этим процессом.
Как работает сканирование?
Сканирование = просмотр. Роботы поисковых систем имеют задачу поиска и поиска максимально возможного количества URL-адресов. Они делают это, чтобы увидеть, есть ли новый контент. Эти URL могут быть новыми или существующими, которые они уже знают. Новые URL просматривают уже известные страницы. После просмотра они передают эти результаты в индекс. Сайты, которые могут сканировать поисковые системы, часто называют « сканируемыми» , то есть поисковыми.
Как работает индексирование?
Индексаторы получают сканеры от сканеров. Затем индексаторы пытаются понять этот контент, анализируя его (включая любые ссылки). Индексатор обрабатывает канонические URL-адреса и определяет полномочия каждого URL-адреса. Индексатор также определяет, следует ли индексировать страницу. Сайты, которые поисковые системы могут индексировать, часто называют индексируемыми , то есть индексируемыми.
Индексаторы также загружают и запускают JavaScript на страницах. Если цель ссылки найдена, данные отправляются обратно сканеру.
Как взять под контроль сканирование и индексирование
Возьмите под контроль процессы сканирования и индексации, четко указав свои предпочтения для поисковых систем. Таким образом, вы поможете им понять, какие части вашего сайта наиболее важны для вас.
В этой главе мы познакомим вас со всеми возможными методами и целесообразностью их использования. Поэтому мы составили для вас таблицу, которая иллюстрирует, что они могут и не могут сделать.
Для начала объясним некоторые термины:
- Crawlable: могут ли поисковые системы сканировать URL?
- Индексируемые: индексируются ли поисковые системы по URL?
- Предотвращает дублирование контента: этот метод предотвращает создание проблемы с дублированным контентом ?
- Консолидация сигналов: поисковым системам рекомендуется объединять сигналы релевантности. Авторитет URL адреса по определению содержания и URL ссылки?
Также важно понимать, как это называется. Сканирование бюджета (бюджет для сканирования). Бюджет сканирования - это время, которое поисковые машины проводят на вашем сайте ежедневно, или количество страниц, которые они ищут за день. Ваш интерес заключается в том, чтобы использовать его максимально разумно и эффективно. И вы можете дать им некоторые инструкции.
Файл Robots.txt

Файл Robots.txt является центральным местоположением, предоставляющим основные правила для сканеров. Эти основные правила называются директивами. Если вы хотите, чтобы сканеры сканировали или не просматривали определенные URL-адреса, файл robots.txt - лучший способ сообщить об этом.
Если роботам не разрешено сканировать URL-адрес и запрашивать его содержимое, индексатор никогда не сможет анализировать содержимое и ссылки. Это может предотвратить дублирование контента, а также означает, что рассматриваемый URL никогда не будет оцениваться поисковой системой. Таким образом, поисковая система не сможет объединить сигналы релевантности и авторитета, потому что они не знают, что находится на сайте. Следовательно, эти сигналы будут потеряны.
Полезный чит для просмотра и индексации
Вы часто задаетесь вопросом, какой метод выбрать, чтобы держать свои поисковые системы под контролем? Экономьте время и просто выбирайте правильные!
Пример использования robots.txt
Раздел Admin на вашем сайте - отличный пример того, когда использовать файл robots.txt для предотвращения сканирования страницы роботами. Допустим, раздел администратора находится по адресу: https://www.example.com/admin/.
Заблокируйте доступ роботов к этому разделу с помощью простой команды robots.txt:
Disallow / admin
Не можете изменить файл robots.txt? Примените директиву meta robots noindex к разделу / admin.
Важные знания
Однако имейте в виду, что URL-адреса, которые вы не просматривали, могут по-прежнему появляться в результатах поиска. Это происходит, когда URL-адреса связаны с другими страницами или уже были проиндексированы поисковыми системами, прежде чем вы получили к ним доступ через robots.txt. Поисковые системы будут предварительно просматривать это следующим образом:
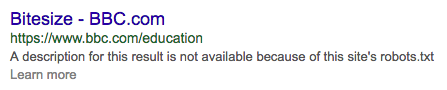
Таким образом, один файл robots.txt не может решить существующие проблемы с дублированным содержимым. Это неправда, что поисковые системы забывают свой URL просто потому, что у них больше нет доступа к нему.
Добавление канонического URL-адреса или метатега noindex роботов к URL-адресу, заблокированному файлом robots.txt, не индексирует его. Поисковые системы никогда не узнают об этом запросе просто потому, что ваш файл robots.txt не позволит им пройти его.
Файл robots.txt также является важным инструментом для оптимизации бюджета сканирования на вашем сайте. С файлом robots.txt вы можете указать поисковым системам, что вам не нужно сканировать те части сайта, которые не имеют к ним отношения.
Что делает файл robots.txt:
- Это не позволит поисковым системам сканировать определенные части вашего сайта, тем самым сохраняя ваш бюджет сканирования.
- Не разрешайте поисковым системам сканировать определенные части вашего сайта - если на них нет ссылок.
- Предотвращает новый дублированный контент.
Что robots.txt не будет делать:
- Он не объединяет сигналы релевантности и авторитета.
- Он не удалит контент, который уже проиндексирован *.
* Хотя Google поддерживает директива noindex и удаляет контент, не рекомендуется использовать этот метод, потому что он не является официальным стандартом. Поддержка Google не означает 100% надежность. Так что используйте его, только если вы не можете его использовать директивы роботов и канонические URL ,
Хотите узнать больше о robots.txt?
Посмотри на наши подробный мастер robots.txt ,

Директивы роботов инструктируют поисковые системы о том, как индексировать страницы, сохраняя страницу доступной для посетителей. Они часто используются в качестве инструкций поисковой системы, чтобы не включать определенные страницы. Когда дело доходит до индексации, это более сильный сигнал, чем канонический URL.
Реализация директив обычно осуществляется путем добавления их в исходный код с помощью мета-тега robots. Для других документов, таких как PDF или изображения, это делается через HTTP-заголовок X-Robots-Tag.
Пример использования директив роботов
Допустим, у вас есть десять целей трафика Google AdWords. Вы скопировали контент с других сайтов, а затем немного отредактировали. Поэтому вы не хотите, чтобы эти целевые страницы были проиндексированы, поскольку они могут вызвать проблемы с дублированием контента. Следовательно, вы должны включить директиву вместе с атрибутом noindex.
Важные знания
Директивы Robtos помогут вам избежать проблем с дублирующимся контентом, но не передают актуальность и авторитет другого URL. Это просто потеряно.
В дополнение к инструкции о том, что поисковые системы не имеют страницы для индексации, директивы мета-роботов noindex также запрещают поисковым системам сканировать страницу. Небольшая часть вашего бюджета сканирования так сэкономлена.
Несмотря на свое мета-имя, атрибут robots nofollow не влияет на сканирование страницы, содержащей атрибут noffolow. Однако, когда установлена директива robots nofollow, роботы не будут использовать ссылки на этой странице для обхода других и не будут передавать полномочия другим страницам.
Что делают директивы роботов:
- Запрещает поисковым системам индексировать определенные части вашего сайта.
- Предотвращает дублирование проблем с контентом.
Что роботы не делают:
- Это не мешает поисковым системам сканировать определенные части сайта и не сохраняет ваш бюджет сканирования.
- Он не объединяет большинство сигналов релевантности и авторитета.
Хотите узнать больше о метатеге роботов?
Проверьте наш полный руководство для мета-тегов роботов ,
Канонические URL

Канонический URL делает каноническую версию страницы доступной для поисковых систем и предлагает поисковым системам индексировать ее. Канонический URL может ссылаться на себя или на другие сайты. Если посетителям полезно получить доступ к нескольким версиям страницы и вы хотите, чтобы поисковые системы рассматривали их как одну версию, использование канонических URL-адресов является правильным способом. Когда одна страница ссылается на другую с помощью канонического URL-адреса, большая часть ее релевантности и полномочий назначается целевому URL-адресу.
Пример использования канонического URL
Допустим, у вас есть интернет-магазин с товаром в трех категориях. Таким образом, один продукт доступен с трех разных URL. Это хорошо для посетителей, но поисковые системы должны сосредоточиться на сканировании и индексации одного URL. Поэтому выберите одну из категорий в качестве основной, а остальные две категории «канонизируйте».
Важные знания
Убедитесь, что 301 постоянно перенаправленных URL-адресов, которые уже удалены, направляют посетителей к канонической версии. Это позволяет вам присвоить всю вашу текущую актуальность и полномочия канонической версии. Это также помогает другим сайтам ссылаться на каноническую версию.
Канонический URL - это скорее руководство, а не руководство. Таким образом, поисковые системы могут также решить игнорировать это.
Применяя канонические URL-адреса, вы не сэкономите свой бюджет сканирования, поскольку это не помешает роботам исследовать сайт. Это предотвратит их появление в поисковых запросах, поскольку они объединены с канонической версией URL.
Что делают канонические URL:
- Запрещает поисковым системам индексировать определенные части вашего сайта.
- Предотвращает дублирование проблем с контентом.
- Объединяет большинство релевантных и авторитетных сигналов.
Что канонические URL не будут делать:
- Это не мешает роботам исследовать определенные части вашего сайта и не сохраняет ваш бюджет сканирования.
Хотите узнать больше о канонических URL?
Посмотрите на подробный каноническое руководство по URL.
Атрибут Hreflang

Атрибут rel = «alternate» hreflang = «x или сокращенно» атрибут hreflang используется, чтобы сообщить поисковым системам, на каком языке контент и для какого региона предназначен сайт. Например, если вы используете один и тот же контент для нескольких регионов, использование hreflang является правильным выбором.
Это позволяет получать результаты с одинаковым контентом на всех рынках и избегать проблем с дублированием контента. В дополнение к дублированию контента, самое главное, чтобы убедиться, что ваш контент связан с целевой аудиторией. Убедитесь, что ваши посетители чувствуют себя как дома, поэтому мы рекомендуем (несколько) различный текст и визуальные элементы, например, для Великобритании и США и так далее.
Пример использования атрибута hreflang
Вы ориентируетесь на несколько англоязычных рынков и используете поддомен для каждого из них. Каждый поддомен содержит одинаковое содержимое:
- www.example.com для рынка США
- ca.example.com для канадского рынка
- uk.example.com для рынка Великобритании
- au.example.com для австралийского рынка
На каждом из них вы хотите получить рейтинг с одинаковым контентом, а также избегать дублирования контента. И тут появляется атрибут hreflang.
Что делает атрибут hreflang:
- Позволяет настроить таргетинг на несколько целевых групп с одинаковым содержанием.
- Предотвращает дублирование проблем с контентом.
Что не делает hreflang:
- Это не препятствует сканированию определенных частей вашего сайта и не сохраняет бюджет сканирования.
- Это не мешает поисковым системам индексировать определенные части вашего сайта.
- Он не объединяет сигналы релевантности и авторитета.
Хотите узнать больше об атрибуте hreflang?
Посмотрите на наши подробные руководство по атрибуту hreflang.
Пейджинг: rel = «prev» и rel = «next»

Ссылки rel = "prev" и rel = "next" используются для того, чтобы сообщить поисковым системам, как связан ряд страниц. Использование атрибутов подкачки настоятельно рекомендуется для ряда похожих сайтов, таких как нумерация блогов или нумерация категорий продуктов. Поисковые системы понимают, что сайты очень похожи, что устраняет проблемы с дублированием контента.
В большинстве случаев поисковые системы не будут ранжировать страницы, кроме первой в серии.
Что делает атрибут подкачки:
- Предотвращает дублирование проблем с контентом.
- Объединяет сигналы релевантности и авторитета.
Что не делает атрибут подкачки:
- Это не препятствует сканированию определенных частей вашего сайта и не сохраняет бюджет сканирования.
- Это не мешает поисковым системам индексировать определенные части вашего сайта.
Хотите узнать больше об атрибутах подкачки?
Посмотрите на наши подробные руководство по поиску ,
Rel = «альтернативный» мобильный атрибут

Мобильный атрибут rel = "alternate" или сокращенно "мобильный атрибут" сообщает поисковым системам взаимосвязь между десктопом и мобильной версией сайта. Это помогает поисковым системам просматривать правильную версию сайта для каждого устройства и предотвращает проблемы с дублированным контентом.
Что делает rel = "alternate" для мобильного телефона:
- Предотвращает дублирование проблем с контентом.
- Объединяет сигналы релевантности и авторитета.
Что rel = "alternate" mobile не делает:
- Это не препятствует сканированию определенных частей вашего сайта и не сохраняет бюджет сканирования.
- Это не мешает поисковым системам индексировать определенные части вашего сайта.
Хотите узнать больше о мобильном атрибуте?
Посмотри на наши атрибут мастера rel = «alternate» mobile

Если у вас нет возможности (быстро) вносить изменения в свой сайт, вы можете настроить параметры в Google Search Console и Bing Webmaster Tools. Обработка параметров определяет, как поисковые системы должны обрабатывать URL-адреса, содержащие параметр. В результате вы можете указать Google и Bing не проходить и / или не индексировать определенные URL-адреса.
Чтобы установить параметры, вам нужны URL-адреса, которые можно идентифицировать по заданному шаблону. Обработка параметров должна использоваться только в определенных ситуациях, таких как сортировка, фильтрация, трансляция и хранение сеансов данных.
Важные знания
Имейте в виду, что настройка этой функции для Google и Bing не повлияет на просмотр других поисковых систем.
Что будут делать настройки параметров:
- Это не позволит поисковым системам сканировать определенные части вашего сайта, тем самым сохраняя ваш бюджет сканирования.
- Запрещает поисковым системам индексировать определенные части вашего сайта.
- Предотвращает дублирование проблем с контентом.
- Объединяет сигналы релевантности и авторитета.
Что настройки параметров не делают:
- Он не позволяет настраивать сканирование и индексацию для отдельных URL-адресов.

HTTP-аутентификация требует входа пользователя или компьютера на веб-страницу (или в раздел). Вот пример того, как это выглядит:
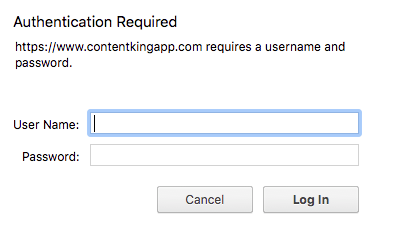
Без вашего (или робота) имени пользователя и пароля вы не сможете пересечь экран входа и ничего не получить. HTTP-аутентификация - отличный способ уберечь нежелательных посетителей - людей и поисковых роботов - от тестовой среды. Google рекомендует запретить роботам доступ к тестовым версиям с использованием HTTP-аутентификации:
Если у вас есть конфиденциальный или частный контент, который не должен отображаться в результатах поиска Google, самый простой и эффективный способ заблокировать частные URL-адреса - это сохранить их на веб-сервере в защищенном паролем каталоге. Робот Googlebot и другие сканеры не могут получить доступ к защищенным паролем каталогам.
Что делает аутентификация HTTP:
- Это не позволит поисковым системам сканировать определенные части вашего сайта, тем самым сохраняя ваш бюджет сканирования.
- Запрещает поисковым системам индексировать определенные части вашего сайта.
- Предотвращает дублирование проблем с контентом.
Что не делает аутентификация HTTP:
- Он не объединяет сигналы релевантности и авторитета.
Полезный чит для просмотра и индексации
Быстро выберите правильный метод для решения проблем сканирования и индексации.
Просматривайте сайт как поисковик: ставьте себя в свои шкуры
Итак, как поисковые роботы смотрят на ваш сайт и отображают его? Окунитесь в их кожу с помощью инструментов "Fetch and Render".
«Загрузить как Google» уже хорошо известно. Он расположен в Google Search Console и позволяет вам ввести URL на вашем сайте, а Google покажет вам, что их сканеры видят по этому URL и как они отображают URL. Вы можете сделать это для настольных компьютеров и мобильных устройств. Смотрите ниже, как это выглядит:
Это отлично подходит для подтверждения, URL-адреса соответствуют ожидаемым требованиям, но также заставляет их индексироваться. Через несколько секунд вы можете получить URL-адрес и проиндексировать его. Это не означает, что его содержимое обрабатывается немедленно и его рейтинг изменяется, но это ускоряет его сканирование и индексирование.
Другие ситуации, когда удобно использовать Load as Google
Получить, как Google, не только полезно для ускорения процесса сканирования и индексации индуктивных URL-адресов, но также позволит вам:
- Ускорьте открытие целых новых разделов на вашем сайте
Загрузите URL, с которого связаны новые разделы, и выберите «Запросить индекс» с параметром «Сканировать этот URL и его прямые ссылки». - Проверьте ваш пользовательский опыт мобильного устройства
Загрузите URL-адреса как «Мобильный телефон: смартфон». - Убедитесь, что перенаправление 301 301 работает правильно
Заполните URL и просмотрите ответ.
Полезно знать:
- Последняя ситуация может быть легко проверена оптом в ContentKing.
- Google позволяет отправлять 500 URL-адресов в месяц для индексации.
- Google позволяет отправлять только 10 URL-адресов в месяц для индексации со ссылками, поскольку все URL-адреса, связанные с этим URL-адресом, также сканируются.
- Bing предлагает аналогичный инструмент под названием " Получить как Bingbot ».
Наиболее часто задаваемые вопросы о сканировании и индексации
1. Как часто Google просматривает мой сайт?
Консоль поиска Google делится с вами вашими методами просмотра. Смотрите это:
- Войдите в консоль поиска Google и выберите веб-страницу.
- Перейдите к разделу «Сканирование»> «Статистика сканирования», чтобы узнать, как часто Google сканирует вашу веб-страницу.
Если вы обладаете техническими знаниями, вы можете узнать, как часто Google сканирует ваш сайт, анализируя файлы журналов вашего сайта.
Стоит знать, что Google определяет, как часто вы должны сканировать свой сайт, используя бюджет для сканирования своего сайта, то есть, используя его. ползти бюджету.
2. Могу ли я замедлить работу роботов при просмотре моего сайта?
Хотя это не рекомендуется для Google и Bing, вы можете использовать директиву ползать задержки для задержки сканирования. Но мы никогда не рекомендуем устанавливать его для Google и Bing, потому что их роботы достаточно умны, чтобы знать, когда ваш сайт перегружен. В этом случае он вернется позже.
3. Как я могу запретить роботам просматривать сайт или сайт?
Есть несколько способов запретить поисковым системам сканировать части вашего сайта или только определенные страницы:
- Файл robots.txt: может использоваться для предотвращения просмотра всего сайта, разделов и отдельных страниц.
- Настройки параметров: могут использоваться для предотвращения сканирования URL-адресов, содержащих параметр.
- HTTP-аутентификация: может использоваться для предотвращения просмотра всего сайта, разделов и отдельных страниц.
4. Что означает индексация сайта?
Это означает, что поисковый оператор пытается определить содержание веб-страницы для правильного поиска.
5. Индексируется ли мой сайт поисковым системам?
Лучший способ ответить на этот вопрос создать учетную запись с ContentKing который оценит, как ваш сайт индексируется поисковыми системами. Как вы уже прочитали, существует множество способов повлиять на то, как поисковые системы индексируют ваш сайт.
6. Как часто Google индексирует мой сайт?
Как часто Google сканирует ваш сайт. Впоследствии роботы передают то, что они нашли, так называемый индексатор, который занимается индексацией веб-страниц.
7. Сколько времени Google тратит на индексацию новых сайтов?
На этот вопрос нет универсального ответа, потому что это зависит от уровня продвижения нового сайта. Продвижение ускоряет процесс сканирования и индексации. Если вы делаете это хорошо, небольшая страница может быть проиндексирована даже через час. Но иногда могут пройти месяцы, прежде чем совершенно новая страница будет проиндексирована.
Обратите внимание, что сайт, проиндексированный поисковой системой, не означает, что ваш сайт автоматически получит хорошее место в результатах поиска. Достижение высокой позиции занимает гораздо больше времени.
8. Как я могу запретить поисковым системам индексировать сайт или сайт?
Вы можете запретить поисковым системам индексировать ваш сайт или сайт, используя следующие методы:
- Метатег роботов noindex: очень сильный сигнал поисковой системы, чтобы не индексировать страницу. Он также не передает релевантные или авторитетные сигналы другим сайтам.
- Канонический URL: является слабым сигналом для поисковых систем о том, какую страницу индексировать и передавать ей релевантность и авторитет.
- Аутентификация HTTP: предотвращает только просмотр и индексирование новых страниц с точки зрения SEO. Тем не менее, по-прежнему рекомендуется использовать HTTP-аутентификацию в тестовых средах, чтобы предотвратить попадание поисковой системы и пользователей.
- Файл robots.txt: может использоваться только для предотвращения сканирования и индексации новых страниц.
- Настройки параметров: могут использоваться для предотвращения сканирования URL-адресов, содержащих параметр.
2. Могу ли я замедлить работу роботов при просмотре моего сайта?
3. Как я могу запретить роботам просматривать сайт или сайт?
4. Что означает индексация сайта?
5. Индексируется ли мой сайт поисковым системам?
6. Как часто Google индексирует мой сайт?
7. Сколько времени Google тратит на индексацию новых сайтов?
8. Как я могу запретить поисковым системам индексировать сайт или сайт?
Есть много методов для этого, так когда вы используете какой метод?
Итак, как взять под контроль весь этот процесс и улучшить свою позицию?



