Вступ
У цьому розділі:
- огляд;
- спрощення, виняток протиріч і зайвих з'єднань;
- перегляд дерева логічних операцій;
У цій статті розглядаються деякі механізми роботи оптимізатора. Вона буде цікава тим, хто хоче більше дізнатися про процес перетворення запиту в план запиту, який і буде переданий сервера на виконання.
Багато засобів, що використовуються в замітці - недокументірованни, з цього, ні в якому разі не рекомендується застосовувати їх на «бойових» серверах. Також, якщо ви хочете виконувати наведені в замітці запити, то рекомендується версія сервера для експериментів «Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600», інакше результат може відрізнятися.
Отже, приступимо.
Процес оптимізації складається з наступних кроків.
1. Parsing
2. Binding
3. Optimization
3.1 Simplification
3.2 Trivial Plan Optimization
3.3 Full Optimization
3.3.1 Search 0
3.3.2 Search 1
3.3.3 Search 2
4. Execution
Parsing - на даному етапі проводиться розбір тексту запиту, перевірка синтаксису і побудова дерева логічних операторів. На виході з даного етапу оптимізатор отримує parsed tree.
Binding - на етапі зв'язування, проводиться дозвіл імен, перевірка на існування таблиць, колонок та інших об'єктів і зіставлення кожного об'єкта дерева з реальним об'єктом системного каталогу.
Optimization: Simplification - етап спрощення дерева. Він включає в себе наступні функції:
- розгортання підзапитів в сполуки (тих, що можливо);
- видалення зайвих з'єднань;
- фільтри з where «пропихати» вниз по дереву, щоб забезпечити раннє фільтрування;
- виявляються і виключаються протиріччя.
На виході з цієї стадії виходить спрощене дерево логічних операторів.
Optimization: Trivial Plan Optimization - пошук тривіального плану. Якщо запит може бути вирішене єдиним або очевидно єдино кращим способом, то значить, запит задовольняє умові тривіального плану. На даному етапі не використовуються рішення на основі статистик, вартості і т.д. Використовується тільки інформація про схему БД (хоча це не зовсім так і ми подивимося на це пізніше). На кожному етапі, починаючи з цього, оптимізація може бути завершена, якщо знайдений досить хороший план, що задовольняє внутрішнім порогам оптимізатора.
Optimization: Full Optimization: Search 0 - цю стадію також називають transaction processing - вона переслідує таку ж мету, як і пошук тривіального плану, знайти хороший план за мінімальний час. На цьому етапі, оптимізатор, на основі евристик, генерує початкові набори можливих варіантів з'єднання, починаючи з сполуки найбільш дрібних (або добре відфільтрованих на ранній стадії) таблиць. Цей порядок, як правило, єдиний, який використовується на даному етапі. Якщо після цієї стадії досить хороший план не знайдений, то управління переходить до наступної стадії. Дана стадія може бути пропущена, і оптимізатор відразу може перейти до стадії 1, якщо запит не відповідає визначеним умовам.
Optimization: Full Optimization: Search 1 - ця стадія так само відома як Quick Plan. На даному етапі використовуються додаткові правила перетворення і деякі можливі перестановки варіантів з'єднання. Якщо після генерації плану на цій стадії, план все ще не достатньо хороший, то дана стадія повторюється з метою пошуку паралельного плану. Після чого два плани порівнюються, і для оцінки вибирається найкращий з них. Якщо цей кращий план все ще не проходить внутрішні пороги оптимізатора, то управління переходить до наступної стадії.
Optimization: Full Optimization: Search 2 - ця стадія відома як Full. Сама остання стадія, а значить, на ній, план повинен бути отриманий в будь-якому випадку, навіть якщо він здається оптимізатора все ще недостатньо хорошим. Ця стадія використовується для складних і дуже складних запитів.
Створимо на тестовому сервері, тестову БД і таблиці (тут і далі я не буду вказувати схему, маючи на увазі, що всі об'єкти знаходяться в схемі dbo).
create database opt; go use opt; go create table t1 (a int primary key, b int not null, c int check (c between 1 and 50)); create table t2 (b int primary key, c int, d char (10)); create table t3 (c int primary key); go insert into t1 (a, b, c) select number, number% 100 + 1, number% 50 + 1 from master..spt_values where type = 'p' and number between 1 and 1000; insert into t2 (b, c) select number, number% 100 + 1 from master..spt_values where type = 'p' and number between 1 and 1000; insert into t3 (c) select number from master..spt_values where type = 'p' and number between 1 and +1000; go alter table t1 add constraint fk_t2_b foreign key (b) references t2 (b);
Тепер, давайте розглянемо кожну стадію Optimization більш докладно. У міру того, як ми будемо дізнаватися нові засоби дослідження, ми будемо повертатися до запитів попередньої стадії для підтвердження висновків.
Отже, приступимо!
Optimization: Simplification
Подивимося на цю фазу більш детально. Включимо опцію Include Actual Plan і виконаємо наступний запит:
select t1.b, t1.c from t1 join t2 on t1.b = t2.b outer apply (select c from t3 where c = 1) t3 where t1.a = 200 and t1.c between 1 and 50 option (recompile )
Що ми можемо очікувати в плані, якщо міркувати логічно. По-перше, з'єднання таблиць t1 і t2, за умовою рівності стовпців t1.b = t2.b, по-друге, для отриманого результату виконання підзапиту з outer apply для кожного рядка, після чого фільтрацію по предикатам t1.a = 200 і t1 .c between 1 and 50.
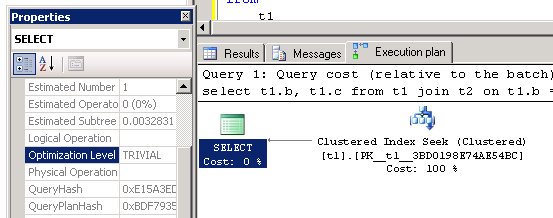
Але замість цього ми бачимо:

Тобто оптимізатор звів все до простого пошуку по кластерному індексу однієї таблиці. Давайте розберемося, чим він керувався, коли це робив.
Почнемо з з'єднання таблиці t2. Якщо ми подивимося на запит, то ніде не побачимо, щоб в результатах була потрібна хоч одна колонка з t2. Але гіпотетично таблиця t2 все ще може впливати на результат запиту, наприклад, зменшивши або збільшивши число рядків, за рахунок умови з'єднання. Однак, згадаємо, як ми визначили таблицю t1, стовпець b там визначено як b int not null, тобто в ньому обов'язково має міститися якесь значення, а, отже, при з'єднанні з нього, результуюче число рядків не може зменшитися (якщо немає додаткових фільтрів в where, звичайно, але у нас їх немає). Але може бути воно може збільшитися? Але згадаємо, що стовпець t2.b визначено як primary key, який містить тільки унікальні значення. Так само згадаємо, що за рахунок обмеження зовнішнього ключа fk_t2_b, в таблиці t1 в стовпці b не можуть з'являтися ніякі інші значення, крім як з таблиці t2. Що ми отримуємо в підсумку, в результуючому запиті стовпців з t2 немає, в умови з'єднання таблиця t2 ні на що не впливає, тому що не може ні додати, ні видалити рядків, а значить, можна її виключити!
Тепер розберемося з apply. Оскільки ми використовуємо outer apply, а не cross apply, то кількість рядків не може зменшитися, навіть якщо підзапит select c from t3 where c = 1 не знайде жодного рядка для умови c = 1. Чи можуть рядка бути додані, якщо підзапит поверне більше одного значення? Ні, тому що у нас умова суворого рівності, а по полю t3.c у нас є первинний ключ, а значить, буде обрана максимум один рядок. Отже, ми отримуємо походжу ситуацію, посилань на колонки таблиці t3 в підсумковому виразі select немає, операція apply не впливає на кількість рядків у результуючому наборі, а значить можна її виключити зовсім!
Тепер переходимо до секції where. Подивимося на предикат t1.c between 1 and 50. Чому ми не бачимо цього порівняння в плані? Справа в тому, що якщо згадати, то ми при визначенні таблиці t1 задали обмеження c int check (c between 1 and 50), виходячи з нього, в цьому стовпці взагалі не можуть міститися інші значення, так навіщо ж ще раз це перевіряти? З цього, ця умова виключається з плану. Більш того, якщо ви зміните в запиті умова, наприклад, на t1.c between 100 and 150, то у вас план прийме і зовсім такий вигляд:

Тобто доступ до таблиць не здійснюватиметься зовсім, тому що свідомо немає значень, які б задовольняли такій умові. При цьому, зрозуміло, все обмеження повинні бути «довіреними», про це я писав тут.
Перейдемо до наступного умові, t1.a = 200, чому ми не бачимо оператор Filter? Тут, справа в тому, що оптимізатор як би «проштовхує» цей предикат, на більш ранню стадію (до виконання з'єднання), на стадію вибору рядків з таблиці t1. Дійсно, навіщо з'єднувати всі рядки, а потім фільтрувати, якщо можна відразу вибрати для з'єднання тільки потрібні, за допомогою індексу. Цей прийом відомий як predicate pushdown.
Що в підсумку. У підсумку залишається єдина операція, виконати пошук потрібних даних в кластерному індексі, причому, це єдина найкраща стратегія застосовна в даному випадку, а значить, план задовольняє умовам trivial plan, і оптимізація на цьому закінчується.
До етапу пошук тривіального плану ми повернемося трохи пізніше, а поки поглянемо на інший запит.
select t1.b, t1.c, d = (select min (c) from t3 where t1.c = t3.c) from t1 option (recompile)
Що б ми могли очікувати в цьому випадку? В цьому випадку можна було б очікувати перегляд таблиці t1, після чого, для кожної знайденої рядки виконання підзапиту до таблиці t3 з агрегацією. Що ми бачимо в результаті:
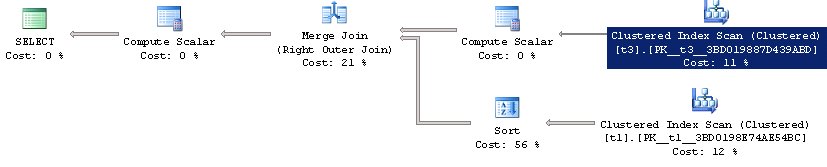

У підсумку, ми бачимо, що було виконано сканування всієї таблиці t3, причому зверніть увагу, зроблено це всього 1 раз. Після чого результати для обох таблиць були об'єднані. Тобто оптимізатор зрозумів, що не потрібно виконувати один і той же 1000 разів, можна заздалегідь обчислити результат і з'єднати з таблицею t1, тобто він «розкрив» наш підзапит (unnest sub query).
Тепер, додамо лише одне слово, яке не змінить результат і логіку, і знову поглянемо на план
select t1.b, t1.c, d = (select top (1) min (c) from t3 where t1.c = t3.c) from t1 option (recompile)

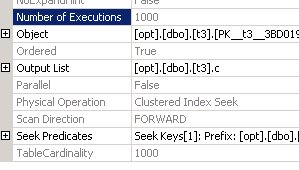
Тут ми бачимо, що план кардинальним чином змінився. Тепер, дійсно прокрутити таблиці t3 і для кожної отриманої рядка (в даному випадку у нас 1000 рядків) виконується пошук за індексом в таблиці t3, після чого агрегування і вибір одного рядка. Все це відбувається 1000 разів. Тобто запит, чи не був розгорнутий, а залишився підзапитом. Чому так?
Справа в тому, що оптимізатор не схильний виконувати операцію unnest для підзапитів з top. Про цю особливість знають і використовують її при написанні t-sql коду, про це використання також знають і розробники сиквел сервера, з цього, поки не поспішають її міняти, але в майбутніх версіях від таких змін ніхто не застрахований.
Наостанок, маленька ремарка по продуктивності. Я думаю, ви вже здогадалися, але все ж, приведу кількість читань і порівняльну вартість планів для обох запитів.
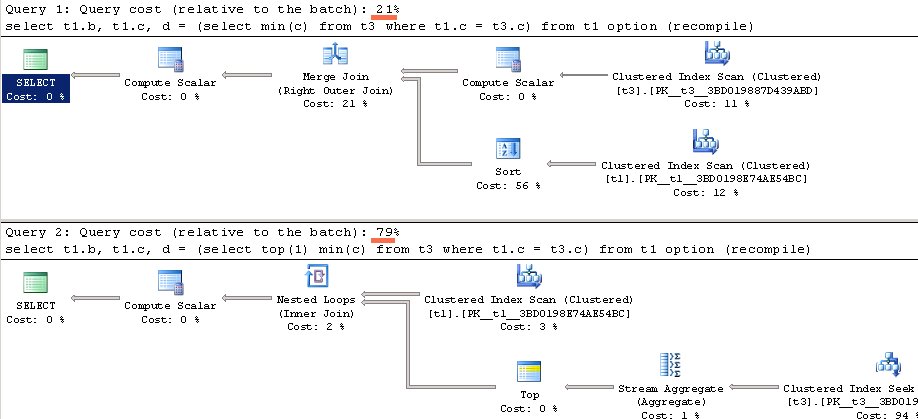
І кількість читань відповідно
(1000 row (s) affected) Table 't1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 't3'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row (s) affected) (1000 row (s) affected ) Table 't3'. Scan count 0, logical reads 2000, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 't1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row (s) affected)
Отже, ми подивилися на деякі етапи фази спрощення. Ок, теорія начебто виглядає переконливо і підтверджується практично. Але чи можна дізнатися, чи дійсно все так відбувається чи ні?
Та й більш того, побачити своїми очима. У цьому нам допоможуть недокументовані прапори трасування. Один з них, широко відомий 3604, він перенаправляє висновок деяких корисних команд з балки на консоль. Інший, менш відомий, 8606 він покаже нам, як перетворюється дерево логічних операторів.
Повернемося до першого запиту і виконаємо його з цими прапорами.
select t1.b, t1.c from t1 join t2 on t1.b = t2.b outer apply (select c from t3 where c = 1) t3 where t1.a = 200 and t1.c between 1 and 50 option (recompile , querytraceon 3604, querytraceon 8606)
Далі перемкнемося на вкладку Messages і ми побачимо дуже цікаву картину. Для зручності я розбив висновок службової інформації на три картинки з поясненнями, а деяку частину опустив.
Отже, ось що ми побачимо:

Наступна фаза, спрощене дерево:

На цьому етапі ми бачимо, що був повністю виключений оператор apply і звернення до таблиці t3, а так же предикат t1.c between 1 and 50. Але з'явився новий логічно оператор, який перевіряє, що значення в колонці c нерівні null. Чому? Тому, що ми визначили для колонки діапазон від 1 до 50, але сама колонка у нас nullable, і отже, хоч і не має сенсу перевіряти діапазон, тому що він забезпечується обмеженням check (c between 1 and 50), але цей предикат все ще може вплинути на результуючий набір виключивши рядки зі значенням null в колонці c. Якби ми спочатку визначили б c як not null - ця гілка б також зникла повністю. Ви можете це самі перевірити, перевизначивши цю колонку як not null.
На цьому етапі, як і раніше залишилося «зайве» з'єднання з таблицею t2.
Переходимо до наступного етапу Join-Collapse, виключенню зайвих з'єднань.

На цьому етапі ми позбулися й таблиці t2. Тепер, все що у нас залишилося в дереві логічних операторів, це отримання даних з таблиці t1, порівняння з константної 200 і перевірка колонки c на not null.
На цьому, в нашому прикладі, етап спрощення завершується.
Ок, ми багато побачили, але питання ще залишилися, перше - як саме оптимізатор «здогадався» застосувати всі ці перетворення, і друге - все-таки, execution engine оперує не логічним деревом, а значить, це не кінцевий етап і далі теж щось то відбувається, де, коли і як відбувається перетворення логічного дерева в фізичні оператори. Відповіді на ці питання, я постараюся дати в наступних розділах присвячених подальшої оптимізації.
1. Чи можуть рядка бути додані, якщо підзапит поверне більше одного значення?
50. Чому ми не бачимо цього порівняння в плані?
1.a = 200, чому ми не бачимо оператор Filter?
Чому так?
Але чи можна дізнатися, чи дійсно все так відбувається чи ні?
Чому?



