Wprowadzenie
W tej sekcji:
- przegląd;
- uproszczenie, wyeliminowanie sprzeczności i niepotrzebnych powiązań;
- wyświetl drzewo drzewa operacji logicznych;
W tym artykule omówiono niektóre mechanizmy optymalizatora. Będzie interesujący dla tych, którzy chcą dowiedzieć się więcej o procesie przekształcania zapytania w plan zapytania, który zostanie wysłany do serwera w celu wykonania.
Wiele narzędzi użytych w notatce nie jest udokumentowanych, więc nie zaleca się używania ich na serwerach „bojowych”. Ponadto, jeśli chcesz wykonać zapytania wymienione w notatce, zalecana jest wersja serwera do eksperymentów „Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600”, w przeciwnym razie wynik może się różnić.
Zacznijmy więc.
Proces optymalizacji składa się z następujących kroków.
1. Przetwarzanie
2. Oprawa
3. Optymalizacja
3.1 Uproszczenie
3.2 Trivial Plan Optimization
3.3 Pełna optymalizacja
3.3.1 Wyszukiwanie 0
3.3.2 Wyszukiwanie 1
3.3.3 Wyszukiwanie 2
4. Wykonanie
Parsowanie - na tym etapie analizowany jest tekst zapytania, sprawdzana jest składnia i budowane jest drzewo operatorów logicznych. Na wyjściu tego etapu optymalizator pobiera analizowane drzewo.
Powiązanie - na etapie wiązania nazwy są rozwiązywane, sprawdzane jest istnienie tabel, kolumn i innych obiektów, a każdy obiekt drzewa jest porównywany z rzeczywistym obiektem katalogu systemowego.
Optymalizacja: uproszczenie - etap upraszczania drzewa. Zawiera następujące funkcje:
- rozmieszczenie podzapytań w związkach (tych, które są możliwe);
- usuwanie nadmiaru związków;
- filtry, z których są „przepychane” w dół drzewa, aby zapewnić wczesne filtrowanie;
- sprzeczności są identyfikowane i wykluczane.
Wyjściem z tego etapu jest uproszczone drzewo operatorów logicznych.
Optymalizacja: Trivial Plan Optimization - poszukaj banalnego planu. Jeśli żądanie może zostać rozwiązane w jeden lub oczywiście jedyny najlepszy sposób, żądanie spełnia warunek trywialnego planu. Na tym etapie decyzje oparte na statystykach, kosztach itp. Nie są wykorzystywane. Używana jest tylko informacja o schemacie bazy danych (choć nie jest to do końca prawdą i zajrzymy do niej później). Na każdym etapie, począwszy od tego, optymalizacja może zostać zakończona, jeśli zostanie znaleziony wystarczająco dobry plan spełniający wewnętrzne progi optymalizatora.
Optymalizacja: pełna optymalizacja: wyszukiwanie 0 - ten etap nazywany jest również przetwarzaniem transakcji - ma taki sam cel, jak poszukiwanie trywialnego planu, aby znaleźć dobry plan w minimalnym czasie. Na tym etapie optymalizator, oparty na heurystyce, generuje początkowe zestawy możliwych opcji łączenia, zaczynając od łączenia najmniejszych (lub dobrze przefiltrowanych na wczesnym etapie) tabel. To zamówienie jest zazwyczaj jedynym stosowanym na tym etapie. Jeśli po tym etapie nie zostanie znaleziony wystarczająco dobry plan, kontrola przechodzi do następnego etapu. Ten etap można pominąć, a optymalizator może natychmiast przejść do etapu 1, jeśli zapytanie nie spełnia określonych warunków.
Optymalizacja: pełna optymalizacja: wyszukiwanie 1 - ten etap jest również znany jako szybki plan. Na tym etapie używane są dodatkowe reguły transformacji i niektóre możliwe permutacje wariantów połączenia. Jeśli po wygenerowaniu planu na tym etapie plan nadal nie jest wystarczająco dobry, etap ten jest powtarzany w celu znalezienia planu równoległego. Następnie porównywane są dwa plany, a najlepszy jest wybierany do oceny. Jeśli ten najlepszy plan nadal nie przekroczy wewnętrznych progów optymalizatora, kontrola przechodzi do następnego etapu.
Optymalizacja: pełna optymalizacja: wyszukiwanie 2 - ten etap jest znany jako pełny. Na ostatnim etapie, co oznacza, że plan musi zostać uzyskany w każdym przypadku, nawet jeśli optymalizatorowi wydaje się, że nadal nie jest wystarczająco dobry. Ten etap jest używany do złożonych i bardzo złożonych zapytań.
Stwórzmy testową bazę danych, testową bazę danych i tabele na serwerze testowym (dalej nie będę wskazywał schematu, co oznacza, że wszystkie obiekty są w schemacie dbo).
utwórz bazę danych opt; idź użyj opt; idź stwórz tabelę t1 (klucz podstawowy int, b int nie null, c int check (c między 1 a 50)); stwórz tabelę t2 (b int klucz podstawowy, c int, d char (10)); utwórz tabelę t3 (c int klucz podstawowy); idź wstaw do t1 (a, b, c) wybierz liczbę, liczbę% 100 + 1, liczbę% 50 + 1 z master..spt_values gdzie type = 'p' i liczbę między 1 a 1000; wstaw do t2 (b, c) wybierz liczbę, liczbę% 100 + 1 z master..spt_values gdzie type = 'p' i liczbę między 1 a 1000; wstaw do t3 (c) wybierz liczbę z master..spt_values gdzie type = 'p' i liczbę między 1 a 1000; go alter table t1 add constraint fk_t2_b klucz obcy (b) odnośniki t2 (b);
Teraz przyjrzyjmy się bliżej każdemu etapowi optymalizacji. Gdy uczymy się nowych narzędzi badawczych, wrócimy do wniosków z poprzedniego etapu, aby potwierdzić ustalenia.
Więc zacznijmy!
Optymalizacja: uproszczenie
Przyjrzyjmy się tej fazie bardziej szczegółowo. Włącz opcję Dołącz aktualny plan i wykonaj następujące zapytanie:
wybierz t1.b, t1.c z t1 połącz t2 na t1.b = t2.b zewnętrzne zastosowanie (wybierz c od t3 gdzie c = 1) t3 gdzie t1.a = 200 i t1.c między 1 a 50 opcją (przekompiluj )
Czego możemy się spodziewać w planie, jeśli myślisz logicznie. Po pierwsze, połącz tabele t1 i t2, zgodnie z warunkiem równości kolumn t1.b = t2.b, po drugie, dla uzyskanego wyniku, wykonaj podzapytanie z zewnętrznym zastosowaniem dla każdego wiersza, a następnie filtruj według predykatów t1.a = 200 i t1 .c między 1 a 50.
Ale zamiast tego widzimy:

To znaczy optymalizator zredukował wszystko do prostego wyszukiwania za pomocą indeksu klastrowego pojedynczej tabeli. Zobaczmy, o co mu chodziło, kiedy to zrobił.
Zacznijmy od tabeli połączeń t2. Jeśli spojrzymy na zapytanie, nie zobaczymy nigdzie, że wyniki wymagają co najmniej jednej kolumny z t2. Ale hipotetycznie, tabela t2 może nadal wpływać na wynik zapytania, na przykład poprzez zmniejszenie lub zwiększenie liczby wierszy z powodu warunku połączenia. Przypomnijmy jednak, jak zdefiniowaliśmy tabelę t1, kolumna b jest zdefiniowana tam jako b int, a nie null, tj. musi zawierać pewną wartość, a zatem, gdy jest przez nią połączony, wynikowa liczba linii nie może się zmniejszyć (jeśli nie ma dodatkowych filtrów, gdzie oczywiście, ale ich nie mamy). Ale może to może wzrosnąć? Pamiętaj jednak, że kolumna t2.b jest zdefiniowana jako klucz podstawowy, który zawiera tylko unikalne wartości. Przypomnijmy również, że ze względu na ograniczenie klucza obcego fk_t2_b, w tabeli t1 w kolumnie b nie mogą pojawić się żadne inne wartości poza tabelą t2. To, co otrzymujemy w końcu, w wynikowym zapytaniu nie ma kolumn z t2, w warunku łączenia tabela t2 nie wpływa na nic, ponieważ nie można dodawać ani usuwać wierszy, co oznacza, że można je wykluczyć!
Zajmijmy się teraz aplikacją. Ponieważ używamy zewnętrznego stosowania, nie stosujemy krzyża, liczba wierszy nie może być zmniejszona, nawet jeśli c zaznaczone z t3 podzapytania, gdzie c = 1 nie znajduje pojedynczego wiersza dla warunku c = 1. Czy wiersze mogą być dodane, jeśli podzapytanie zwraca więcej niż jeden wartości? Nie, ponieważ mamy warunek ścisłej równości, aw polu t3.c mamy klucz podstawowy, co oznacza, że zostanie wybrany najwyżej jeden wiersz. Tak więc mamy podobną sytuację, nie ma żadnych odniesień do kolumn tabeli t3 w końcowej instrukcji select, operacja stosowania nie wpływa na liczbę wierszy w zestawie wyników, co oznacza, że można go całkowicie wyeliminować!
Teraz przejdź do sekcji gdzie. Spójrzmy na predykat t1.c między 1 a 50. Dlaczego nie widzimy tego porównania w planie? Faktem jest, że jeśli przypomnimy sobie, definiując tabelę t1, ustawimy ograniczenie c int check (c między 1 a 50), na tej podstawie kolumna ta nie może w ogóle zawierać innych wartości, więc po co ponownie to sprawdzać? Dlatego warunek ten jest wyłączony z planu. Ponadto, jeśli zmienisz warunek w żądaniu, na przykład na t1.c między 100 a 150, wtedy twój plan przyjmie następującą postać:

To znaczy dostęp do stołów w ogóle nie zostanie wykonany, ponieważ Z pewnością nie ma wartości, które spełniłyby ten warunek. W tym przypadku oczywiście wszystkie ograniczenia muszą być „zaufane”, pisałem o tym tutaj.
Przejdźmy do następnego warunku, t1.a = 200, dlaczego nie widzimy operatora Filter? W tym przypadku faktem jest, że optymalizator „popycha” ten predykat, jak to miało miejsce wcześniej, przed wykonaniem połączenia, na etapie wybierania wierszy z tabeli t1. Rzeczywiście, po co łączyć wszystkie wiersze, a następnie filtrować, jeśli można od razu wybrać tylko te, które chcesz dołączyć, używając indeksu. Ta technika jest znana jako upadek predykatu.
Jaki jest wynik. W rezultacie jedyną operacją, która pozostaje, jest przeprowadzenie wyszukiwania niezbędnych danych w indeksie klastra, i jest to jedyna najlepsza strategia mająca zastosowanie w tym przypadku, co oznacza, że plan spełnia warunki trywialnego planu, a na tym kończy się optymalizacja.

Powrócimy do etapu szukania trywialnego planu nieco później, ale na razie przyjrzyjmy się kolejnej prośbie.
wybierz t1.b, t1.c, d = (wybierz min (c) z t3, gdzie t1.c = t3.c) z opcji t1 (przekompiluj)
Czego możemy się spodziewać w tym przypadku? W tym przypadku można by oczekiwać spojrzenia na tabelę t1, po której dla każdego znalezionego wiersza należy wykonać podzapytanie do tabeli t3 z agregacją. Co widzimy w końcu:
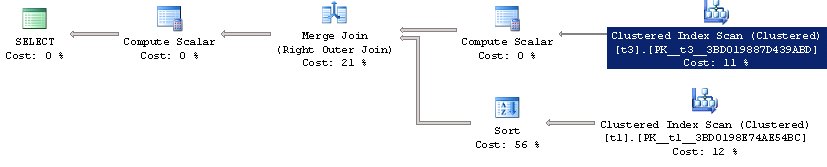
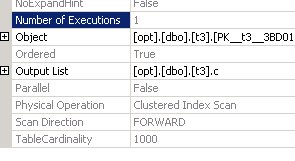
W rezultacie widzimy, że cała tabela t3 została zeskanowana i zauważono, że zostało to zrobione tylko raz. Następnie wyniki dla obu tabel zostały połączone. To znaczy Optymalizator zdał sobie sprawę, że nie było konieczne wykonanie tego samego 1000 razy, można obliczyć wynik z wyprzedzeniem i połączyć się z tabelą t1, tj. on „otworzył” nasze podkwerendę (nieodebrane zapytanie dodatkowe).
Teraz dodaj tylko jedno słowo, które nie zmienia wyniku i logiki, a następnie spójrz na plan
wybierz t1.b, t1.c, d = (wybierz górę (1) min (c) z t3 gdzie t1.c = t3.c) z opcji t1 (przekompiluj)


Tutaj widzimy, że plan radykalnie się zmienił. Teraz tabela t3 jest faktycznie skanowana, a dla każdego otrzymanego wiersza (w tym przypadku mamy 1000 wierszy), wyszukiwanie odbywa się za pomocą indeksu w tabeli t3, po którym następuje agregacja i wybór jednego wiersza. Wszystko to dzieje się 1000 razy. To znaczy Zapytanie nie zostało wdrożone, ale pozostało podzapytaniem. Dlaczego tak
Faktem jest, że optymalizator nie jest skłonny do wykonywania najsurowszej operacji dla podzapytań z górnym. Ta funkcja jest znana i używana przez niego podczas pisania kodu t-sql, serwery sequel serwera również wiedzą o tym użyciu, więc nie spieszą się z jego zmianą, ale w przyszłych wersjach nikt nie jest ubezpieczony od takich zmian.
Wreszcie mała notatka wydajności. Myślę, że zgadłeś, ale mimo to podam liczbę odczytów i względny koszt planów dla obu zapytań.

I odpowiednio liczba odczytów
(Dotyczy 1000 wierszy) Tabela „t1”. Odczyty fizyczne 0, odczyt z wyprzedzeniem odczytuje 0, odczyty logiczne lob 0, odczyty fizyczne lob 0, odczyt z wyprzedzeniem lob odczytuje 0. Tabela „t3”. Odczyty fizyczne 0, odczyt z wyprzedzeniem odczytuje 0, odczyty logiczne lob 0, odczyty fizyczne lob 0, odczyt z wyprzedzeniem lob odczytuje 0. (dotyczy 1 wiersza) (dotyczy 1000 wierszy) ) Tabela „t3”. Odczyty fizyczne 0, odczyt z wyprzedzeniem odczytuje 0, odczyty logiczne lob 0, odczyty fizyczne lob 0, odczyt z wyprzedzeniem lob odczytuje 0. Tabela „t1”. Odczyty fizyczne 0, odczyt z wyprzedzeniem odczytuje 0, odczyty logiczne lob 0, odczyty fizyczne lob 0, odczyt z wyprzedzeniem lob odczytuje 0 (1 wiersz dotyczy)
Przyjrzeliśmy się zatem niektórym etapom fazy uproszczenia. Ok, teoria wydaje się być przekonująca i praktycznie potwierdzona. Ale czy można się dowiedzieć, czy wszystko się naprawdę dzieje, czy nie?
A co więcej, zobacz na własne oczy. W tym pomogą nam nieudokumentowane flagi śledzenia. Jeden z nich, dobrze znany 3604, przekierowuje dane wyjściowe niektórych użytecznych poleceń z dziennika do konsoli. Inny, mniej znany, 8606, pokaże nam, jak przekształcane jest drzewo operatorów logicznych.
Wróćmy do pierwszego żądania i wykonaj je z tymi flagami.
wybierz t1.b, t1.c z t1 połącz t2 na t1.b = t2.b zewnętrzne zastosowanie (wybierz c od t3 gdzie c = 1) t3 gdzie t1.a = 200 i t1.c między 1 a 50 opcją (przekompiluj , querytraceon 3604, querytraceon 8606)
Następnie przejdź do karty Wiadomości i zobaczymy bardzo ciekawy obraz. Dla wygody złamałem wyjście informacji o usługach na trzy zdjęcia z objaśnieniami i obniżyłem niektóre z nich.
Oto co zobaczymy:

Następna faza, uproszczone drzewo:

Na tym etapie widzimy, że operator Apply został całkowicie wyeliminowany i odwołuje się do tabeli t3, a także predykatu t1.c od 1 do 50. Ale pojawił się nowy operator logiczny, który sprawdza, czy wartości w kolumnie c nie są równe null. Dlaczego Ponieważ zdefiniowaliśmy zakres dla kolumny od 1 do 50, ale sama kolumna jest pusta, a zatem, choć nie ma sensu sprawdzać zakresu, ponieważ jest on dostarczany przez ograniczenie sprawdzające (c między 1 a 50), ale ten predykat może nadal wpływać na zestaw wyników, wykluczając wiersze o wartości NULL w kolumnie c. Gdybyśmy najpierw zdefiniowali c jako nie zerowy, ta gałąź również zniknie całkowicie. Możesz to sprawdzić samodzielnie, zastępując tę kolumnę jako niezerową.
Na tym etapie nadal istnieje „dodatkowe” połączenie z tabelą t2.
Przechodzimy do następnego etapu Join-Collapse, eliminacji niepotrzebnych połączeń.

Na tym etapie pozbyliśmy się tabeli t2. W drzewie operatorów logicznych pozostało nam tylko pobieranie danych z tabeli t1, porównywanie ze stałą 200 i sprawdzanie kolumny c, czy nie ma wartości null.
W tym przypadku w naszym przykładzie etap uproszczenia został zakończony.
Ok, widzieliśmy dużo, ale wciąż są pytania, po pierwsze, w jaki sposób optymalizator „zgadł”, aby zastosować wszystkie te transformacje, a drugi jest nadal, silnik wykonawczy nie działa z drzewem logicznym, co oznacza, że nie jest to etap końcowy i dalej co się dzieje, gdzie, kiedy i jak drzewo logiczne jest przekształcane w operatorów fizycznych. Odpowiedzi na te pytania postaram się podać w poniższych sekcjach poświęconych dalszej optymalizacji.
1. Czy wiersze mogą być dodane, jeśli podzapytanie zwraca więcej niż jeden wartości?
50. Dlaczego nie widzimy tego porównania w planie?
1.a = 200, dlaczego nie widzimy operatora Filter?
Ale czy można się dowiedzieć, czy wszystko się naprawdę dzieje, czy nie?



